정적 웹페이지(Static Web Page) 스크래핑
HTML문서에서 원하는 정보 추출하기
BeautifulSoup
python에서 scraping 하는데 필요한 함수를 모아놓은 라이브러리
html_str = """
<html>
<head>
<title>Intro to Web Scraping</title>
</head>
<body>
<div>First div</div>
<div>Second div</div>
</body>
</html>
"""위의 stml_str에 저장되어있는 값은 단순 문자열
이를 parsing하기 위해서 이 문자열이 HTML문서라는 것을 알게해줘야 함
- 파싱(parsing): 텍스트의 구성 성분을 분해한다는 의미
- ex) You need Python → You/need/Python
HTML을 BeautifulSoup으로 scraping하기
# <head> 부분 찾기
bs_obj = BeautifulSoup(html_str, 'html.parser')
head = bs_obj.find('head')
# find로 생성된 결과물은 Tag라는 클래스의 객체(object)
print(type(head))
print(head.__class__.__name__)
# <class 'bs4.element.Tag'>
# Tag
# 객체의 속성(attribution) 사용 가능
# text라는 속성 사용 → 내부 문자열만 추출 가능
head.text
# <body> 부분 찾기
body = bs_obj.find('body')
# <div> 부분 찾기
div = bs_obj.find('div') # find 메소드 사용시, 첫번째 결과만 반환
div = bs_obj.find_all('div') # find_all 메소드 사용시, 모든 결과 반환로컬 HTML 파일 열기
<!DOCTYPE html>
<html>
<head>
<title>make table example</title>
</head>
<body>
<table border="1">
<caption> first table</caption>
<th>column 1</th>
<th>column 2</th>
<tr>
<td>first row 1</td>
<td>first row 2</td>
</tr>
<tr>
<td>second row 1</td>
<td>second row 2</td>
</tr>
</table>
<table border="2">
<caption> second table</caption>
<th>column 1</th>
<th>column 2</th>
<tr>
<td>first row 1</td>
<td>first row 2</td>
</tr>
<tr>
<td>second row 1</td>
<td>second row 2</td>
</tr>
</table>
</body>
</html>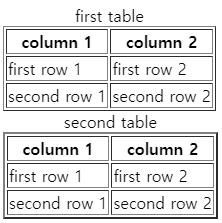
bs_obj = BeautifulSoup(open("practice05.html", encoding="utf8"), "html.parser")
# table내의 내용 추출
table = bs_obj.find_all('table')
# 태그와 속성을 함께 이용해 추출
second_table = bs_obj.find_all('table', {'border':'2'})실제 웹페이지 scraping
web page| https://irisyj.tistory.com/75
F12 키 눌러서 소스코드 열기
제목, 본문 내용 scraping <h> <p>
from urllib.request import urlopen
from bs4 import BeautifulSoup
# urllib 라이브러리 사용해서 웹페이지 열기
url = 'https://irisyj.tistory.com/75'
html = urlopen(url)
# BeautifulSoup로 태그 기준 parsing
bs_obj = BeautifulSoup(html, 'html.parser')
# <h3> 태그에 해당하는 내용 모두 찾기
title = bs_obj.find_all('h3')
# 글 제목에 해당하는 내용 찾기
print(title[0].text)
# [텍데분] Web Scraping 1
# <p> 태그에 해당하는 내용 모두 찾기
contents = bs_obj.find_all('p')
for tex in contents:
print(tex.text)table 내용 scraping <table> <td>
from urllib.request import urlopen
from bs4 import BeautifulSoup
# urllib 라이브러리 사용해서 웹페이지 열기
url = 'https://irisyj.tistory.com/75'
html = urlopen(url)
# BeautifulSoup로 태그 기준 parsing
bs_obj = BeautifulSoup(html, 'html.parser')
# 방법 1
# <table> 태그에 해당하는 내용 모두 찾기
table = bs_obj.find_all('table')
# 원하는 table에서 원하는 내용에서 <td> 태크 내용 찾기
td = table[1].find_all('td')
for t in td:
print(t.text)
# 방법 2
# <td> 태그 속성 지정해서 해당하는 내용 찾기
td = bs_obj.find_all('td', {"style":"width: 11.2791%;"})목록 정보 추출 <ul> <li>
from urllib.request import urlopen
from bs4 import BeautifulSoup
# urllib 라이브러리 사용해서 웹페이지 열기
url = 'https://irisyj.tistory.com/75'
html = urlopen(url)
# BeautifulSoup로 태그 기준 parsing
bs_obj = BeautifulSoup(html, 'html.parser')
# <ul> 태그 속성 지정해서 해당하는 내용 찾기
ul = bs_obj.find_all('ul', {'style':"list-style-type: disc;", 'data-ke-list-type':"disc"})
# <li> 태그로 텍스트만 추출하기
li = ul[0].find_all('li')
for t in li:
print(t.text)
'2023_국민대 > 텍스트 데이터 분석' 카테고리의 다른 글
| [텍데분] Web Scraping 3 (0) | 2023.04.16 |
|---|---|
| [텍데분] Web Scraping 1 (0) | 2023.04.15 |
| [텍데분] Regular Expression 3 (0) | 2023.04.12 |
| [텍데분] Regular Expression 2 (0) | 2023.04.12 |
| [텍데분] Regular Expression 1 (0) | 2023.04.12 |



