U-Net: Convolutional Networks for Biomedical Image Segmentation
paper| https://arxiv.org/abs/1505.04597
Biomedical 분야에서 Image Segmentation을 목적으로 제안된 End-to-End 방식의 Fully-Convolutional Network 기반 모델
Network 구성 형태가 U자 모양이어서 U-Net이라는 이름이 붙여짐
이미지의 전반적인 컨텍스트 정보를 얻기 위한 네트워크와 정확한 Localization을 위한 네트워크가 대칭 형태로 구성
Contracting Path → 수축단계
입력 이미지의 Context 포착을 목적으로 구성
FCNs 처럼 VGG-based Architecture
Expanding Path → 팽창단계
세밀한 Localization을 위한 구성
높은 차원의 채널을 갖는 Up-sampling
얕은 레이어의 특징맵을 결합
Abstract
deep network를 성공적으로 training 시키기 위해서는 수천 개의 주석이 달린 training sample이 필요
본 논문에서는, 주석이 달린 sample을 더 효율적으로 사용하기 위해 data augmentation 사용에 의존하는 network 및 training 전략을 제시
architecture 구성
- contracting path : context를 캡쳐
- symmetric expanding path: 정확한 localization를 가능하게 함
이러한 network는 End-to-End로 train될 수 있음 & electron microscopic stack에서 neuronal structure의 segmentation을 위한 ISBI challenge에서 이전의 best method(sliding-window convolutional network)를 능가함
ISBI cell tracking challenge 2015에서 큰 차이로 우승
속도도 빠름 (논문 발표 당시 GPU로 512X512 이미지 segmentation에서 1초 미만 걸림)
1 Intoduction
지난 2년 간(본 논문은 2015년), deep convolutional network는 많은 visual recognition task에서 SOTA을 능가함
이용가능한 training set의 크기와 고려된 network의 크기로 성공이 제한됐음
1백만개의 training image가 있는 ImageNet dataset에서 8개의 layer와 수 백삼의 parameter를 가진 큰 network의 지도학습 덕분 (AlexNet)
이 이후로 훨씬 더 크고 deep한 network가 훈련되었음
convolutional network의 일반적인 사용은 image에 대한 ouput이 단일 class label인 classification task였음

2 Network Architecture
network architecture는 Figure 1에 나와있음
contracting path (왼쪽) & expansive path (오른쪽) 으로 구성
contracting path
convolutional network의 일반적인 architecture를 따름
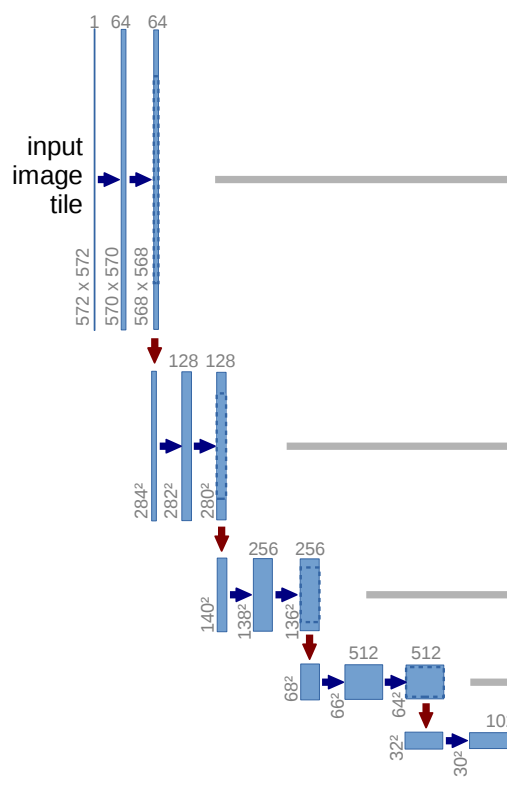
- 두개의 3X3 convolution 적용 (conv 할 때, ReLU 적용) → padding이 없어서 feature map이 조금씩 줄어듦
- 각각은 downsampling을 위한 2X2 max pooling (stride 2)작업으로 구성 → feature map의 크기 절반으로 줄어듦
- downsampling 할 때마다, channel 수가 2배로 늘어남
expansive path
feature channel 수를 두 배로 늘림

- feature map의 upsampling 진행
- 2X2 convolution (up-convolution) : feature channel의 수를 절반으로 줄임
- 두 개의 3x3 convolution & ReLU 포함 (padding 없음)
- Up-conv된 feature map과 contracting path로부터 crop된 feature map과 연결
마지막 layer에서 1X1 convolition을 사용하여 각 64개 component feature vector를 원하는 class 수에 매핑
network에는 총 23개의 convolutional layer가 있음
output segmentation map의 원활한 tiling을 위해서 (Figure2 참조), 모든 2X2 max-pooling 작업이 짝수 x & y 크기의 layer에 적용되도록 input tile 크기를 선택하는 것이 중요

최종 output인 segmentation map의 크기는 input Image 크기보다 작음 → conv 연산에서 padding을 사용하지 않았기 때문
3 Training
3.1 Data Augmentation
data augmentation은 이용가능한 training sample이 적을 때, 원하는 불변성 & 견고성을 network를 학습하기 위해서 필수적임
미시적인 image의 경우, 우선 변형 및 회색 값 변화에 대한 견고성뿐만아니라 shift 및 rotation 불변성도 필요
특히, training sample의 random elastic 변형은 주석달린 image가 매우 적은 segmentation network를 trian하기 위해 key concept인 것 같음
coarse 3X3 grid에서 무작위 변위 vector를 사용하여 smooth 변형을 생성
변형은 10pixels 표준 편차를 갖는 Gaussian 분포에서 샘플링됨
pixel 당 변위는 bicubic 보간법을 사용하여 계산
contracting path 끝에 있는 drop-out layer는 추가적으로 암시적 data augmentation을 수행
4 Experiments
5 Conclusion
U-Net architecture은 매우 다른 biomedical segmentation application에서 좋은 성능을 달성
융통성있는 변형을 통한 data augmentation 덕분에 주석달린 image가 매우 적게 필요하고, 매우 합당한 training 시간을 가짐 (NVidia Titan GPU (6GB)에서 10시간)
본 저자들은 U-Net architecture은 더 많은 task에 쉽게 적용할 수 있을 것이라고 확신함
'공부 끄적끄적 > 논문리뷰' 카테고리의 다른 글
| [paper reivew] BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer (0) | 2023.04.30 |
|---|---|
| [X:AI] RetinaNet; Focal Loss for Dense Object Detection (0) | 2023.04.07 |
| [X:AI] ELMo; Deep Contextualized Word Representations (0) | 2023.03.31 |
| [X:AI] Transformer; Attention Is All You Need (0) | 2023.03.23 |
| [2022D&A] DCGAN (0) | 2022.08.17 |



